


Across industries, organizations are investing heavily in data architecture to generate analytics to support business decisions. Effective data analytics rely heavily on the ways in which data is collected, loaded, transformed, stored, queried, and secured.
Data that’s processed as it arrives in real time or near real time, is referred to as streaming data, while data that’s accumulated before being processed is referred to as data at rest.
Both types of data processing have their own advantages. Data at rest is ideal for managing database updates and processing transactions, as large amounts of this type of data can be processed efficiently with minimal need for user interaction.
Conversely, streaming data works well in applications like modern business intelligence tools. As streaming data is analyzed almost instantly upon being stored, it can help automatically generate reports and actionable information, such as real-time customer shopping insights; it can also quickly detect anomalies.
Streaming data effectively supports quick business decisions and thus elevates competitiveness and customer satisfaction.
This article compares streaming data and data at rest, their use cases, and the differences between the architecture and pipelines for processing both types of data. Finally, the article also provides a brief introduction to turning batch data into streaming data.
Streaming Data and Data At Rest
Streaming data and data at rest require very different methods of storage and analysis. Data at rest is stored in a database before it’s processed, while streaming data is generated continuously and often simultaneously from multiple data sources and analyzed almost at the time it’s collected.
Sending large amounts of data in batches helps minimize user interaction, thus saving labor costs while increasing efficiency. It’s not surprising, then, that industries such as banking, healthcare, utility providers, and logistics have traditionally relied on at rest data.
For example, banks produce reports on customers’ daily credit card transactions by processing batches of data overnight, and utility companies determine customer billing through a pipeline that analyzes data at rest collected on a daily basis.
However, the time between the data being generated (eg, when a customer views an item on a website) and when it appears in data storage can be quite long. This delay is known as high latency. As it has to wait for historical records to accumulate, data at rest has significant speed limitations and consequently does not support quick decision-making.
In contrast, streaming data has low latency, allowing companies to react to circumstances essentially in real time. For example, e-commerce platforms can analyze the stream of log files generated when customers engage with mobile and web applications to identify anomalies, fraudulent activities, and high-risk transactions in real time and respond instantly.
Additionally, as streaming data is updated in real time to display what’s occurring every second, it facilitates real-time analytics, which is imperative in time-critical situations. For example, ride-hailing apps could provide adaptive price changes and allocate drivers to meet surge demands during events such as the end of the work day.
Companies can also use streaming data to track changes in public sentiment toward their brands, get instant product feedback, and determine campaign performance with existing and new customers by analyzing real-time social media discussions and click streams (a sequence of links that a customer clicks on).
Stream Processing and Batch Processing
As data at rest relies on batch processing, and streaming data relies on stream processing, their pipelines are quite different. While stream processing processes the data right after it’s collected from sources, batch processing processes the data after it has been generated and stored in a data warehouse.
Stream Processing
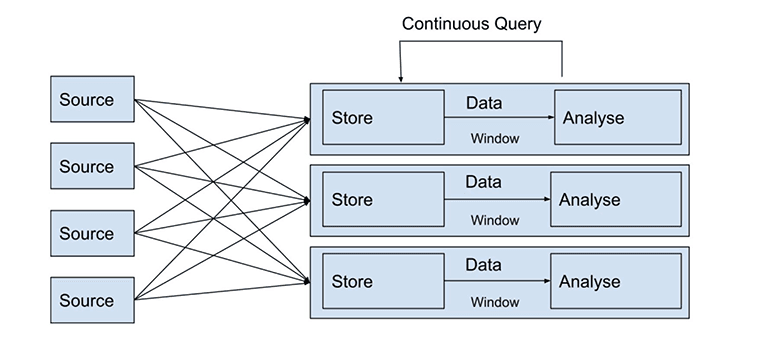
Stream processing is the collection and analysis of continuous streams of data immediately (a few seconds or milliseconds) after being generated. A stream processor processes data in a few passes and the rate of data output corresponds approximately to the rate of input. This eliminates the delays of data processing and is most suitable for handling continuous data.
For instance, stream processing in cybersecurity helps identify DDoS attacks through log monitoring; it can detect suspicious traffic from specific IP addresses and device IDs.
Real-time personalization is another common use case of stream processing. Based on real-time user enrollment through the customer funnels, and what they put in their shopping carts, the company can accordingly build real-time personalization and recommendation systems.
If you respond to customers’ needs promptly, you provide a better shopping experience for customers. This improved experience leads to happier customers who are more likely to spend, thus increasing their total order value.
Batch Processing
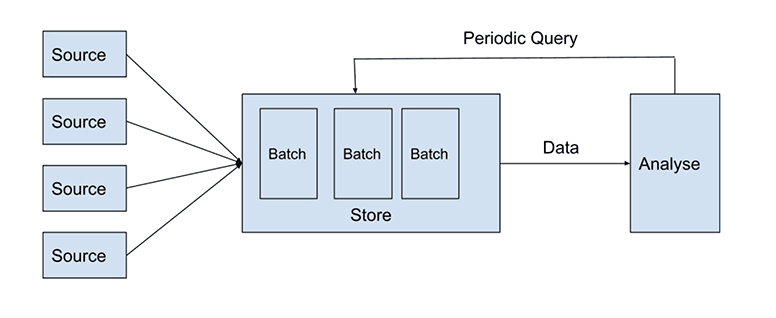
Batch processing relates to the collection of large-scale non-continuous data and grouping them in batches. Batch processing is more advantageous when data size is both known and finite. Unlike streaming processors, batch processors handle a high quantity of data all at once and send them in multiple passes to the target data warehouse.
Companies usually implement the ETL process (extract, transform, load) as a form of batch processing: unstructured data is collected from external sources and transformed into different formats (normally structured data) and then loaded into data storage before the analysis is conducted. As mentioned earlier, batch processing can handle multiple jobs concurrently with minimum user interaction, so it’s often used to manage a great deal of data that doesn’t require real-time responses.
For instance, logistics companies are able to offer fast and accurate delivery of goods and services such as same-day delivery, next-day delivery, or same-location delivery partly due to processing orders in batches.
Comparing Stream Processing and Batch Processing
Batch data processing methods require data to be downloaded in batches before it can be processed, stored, or analyzed, while streaming data flows continuously, allowing for data to be processed in real-time the moment it's generated.
However, as data is only analyzed after being processed, businesses that rely on batch data can only make informed decisions after the analysis is complete. Conversely, in stream processing, data is collected and analyzed at the same time, allowing businesses to respond to emerging circumstances almost instantly.
In batch processing, if one operation is delayed, it holds up the pipeline because the next job cannot start. Additionally, once there’s an error in the pipeline, the operators or IT professionals need to trace the source of that error, eg, which rows, columns, or data sets have that error, as well as the potential impact. Therefore, personnel need proper training to debug issues.
Investigating errors in stream processing is comparatively less tedious, because stream processing can compute a relatively short window of recent data. It allows you to isolate the problematic stream of events without the need to identify the different sources of data in that window.
Turning Batch Data into Streaming Data
As streaming data has low latency and can thus power real-time analytics, more and more industries are using it to close the gap between data processing and decision-making.
For instance, streaming data can be used to monitor key indicators and trigger alarms when they surpass or fall behind certain thresholds; it can also support real-time machine learning algorithms, which, for example, recommend products to customers at the right time in their engagement with a company website.
Hence, there’s an increasing need to transform batch data into streaming data. To do so, companies need to build data architecture that can accommodate the transformation. A standard data streaming architecture has three components:
- An event hub that ingests multiple related events from different sources.
- A message broker that simplifies the communication between applications by translating data into a commonly consumable format.
- An analytics engine that analyzes the stream data.
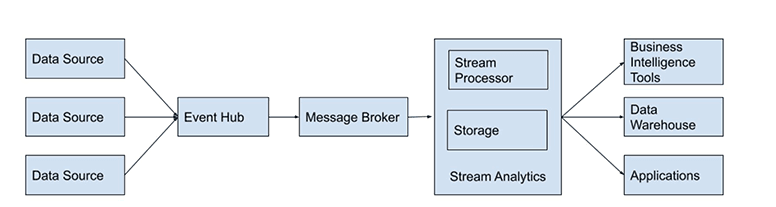
The event hub is the storage that collects different events from multiple data sources. It’s a data ingestion service that makes sure data is collected sequentially.
Message brokers, as the name suggests, collect data from sources, validate and translate it into a standard message format, and continuously send it to target destinations such as data warehouses or streaming analytics engines. Therefore, message brokers act as intermediaries and simplify communication between applications, as every application after that process “speaks” the same messaging language.
As streaming data is continuously created and analyzed, stream analytics has two stages that are conducted simultaneously: storage and processing.
To support the ordering and consistency of the data, the storage stage must be able to support reads and writes of huge streams of data that are quick and repeatable. Then, the processing stage consumes data from the storage stage, processes it, and finally communicates to the storage layer to delete records that are no longer required.
After these steps, data can be visualized through business intelligence tools or received by enterprise applications for consumption.
Conclusion
In summary, batch data and stream data have specific benefits in different use cases. Understanding the similarities and differences between these types of data can enable companies to build suitable data architecture and turn batch data into streaming data when the need arises.
Adopting a solution like Bytewax, an open source Python framework for building highly scalable dataflows, which can process any data stream, can help make these processes and transformation from batch to streaming much less challenging.
Bytewax can handle independent elements of the data simultaneously and continuously. It provides hassle free development by allowing developers to create and run codes locally; Bytewax can then easily scale that code to multiple workers or processes without changes.
Have more questions about streaming data? Come join our community slack channel!.
Other posts you may find interesting
View all articles

Kafka Data Enrichment
Data enrichment is the process of adding to or enhancing data to make it more suitable or useful for a specific purpo...
Written by Zander Matheson & Osinacha Chukwujama